| |
Download PennCNV PennCNV is a software originally developed for CNV detection from Illumina whole-genome SNP genotyping arrays. It has been extended to handle candidate gene SNP arrays, to handle recent high-density arrays with non-polymorphic markers (so-called CN markers), and to handle Affymetrix genome-wide arrays. PennCNV-Affy is a collection of data pre-processing protocols and helper scripts that convert Affymetrix CEL files into a data format suitable for CNV detection by PennCNV. 1 PennCNV main package
The link to latest version (2011Jun16 version) of PennCNV main package is given below. The package includes both source codes and pre-compiled executables for several commonly used system architecture, including 32-bit Windows. (Due to the problem of several unzipping software under Windows in handling *.tar.gz files, Windows users should try to download the zip file instead. The contents of these two files are identical). Files were updated 2011Jun28 to fix a small packaging issue. DO NOT STOP HERE, READ THE PARAGRAPHS BELOW TO DOWNLOAD UPDATED FILES. User-supplied PFB files: Users can use the compile_pfb.pl program included in PennCNV to generate a PFB file for their specific arrays.
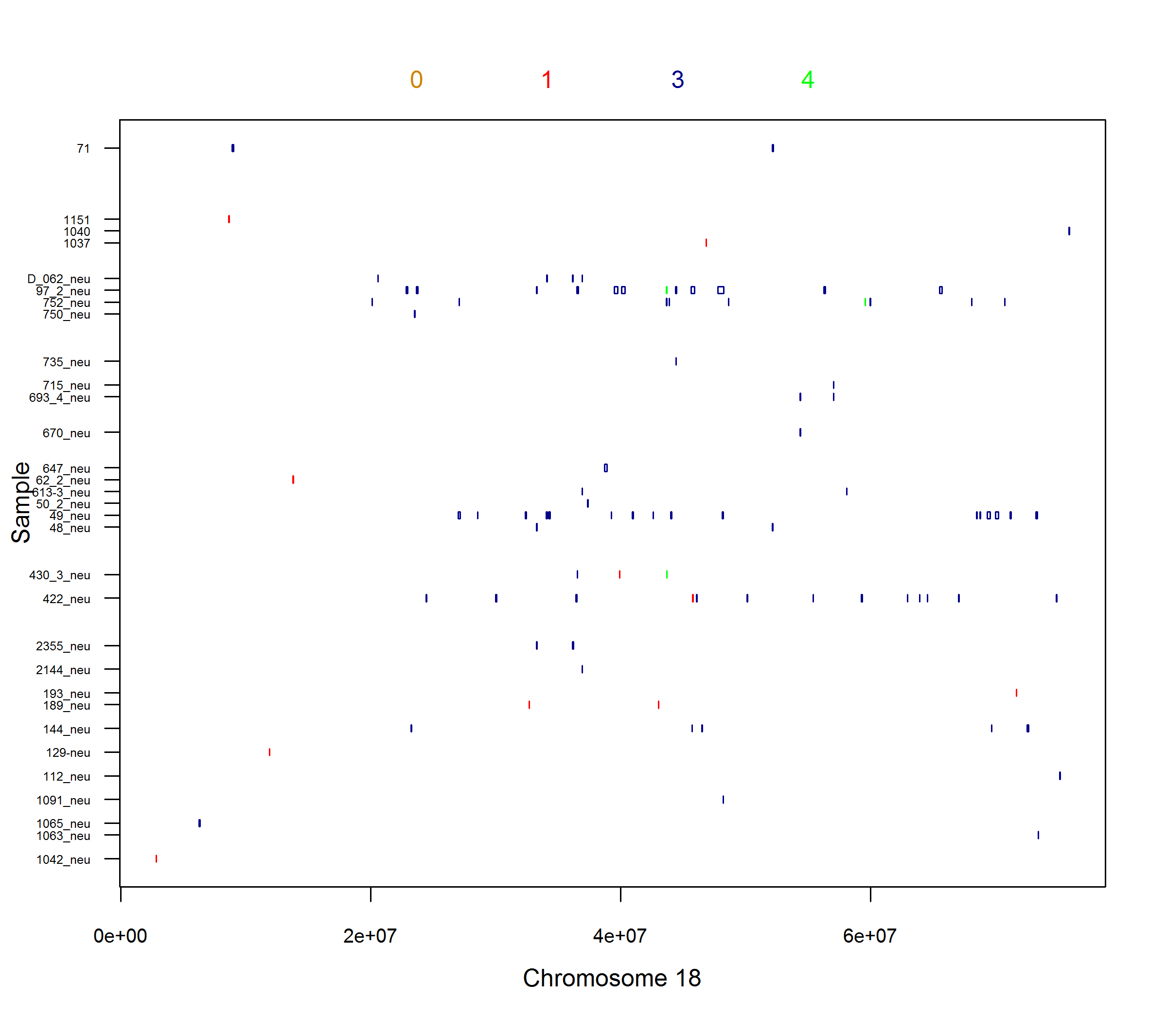
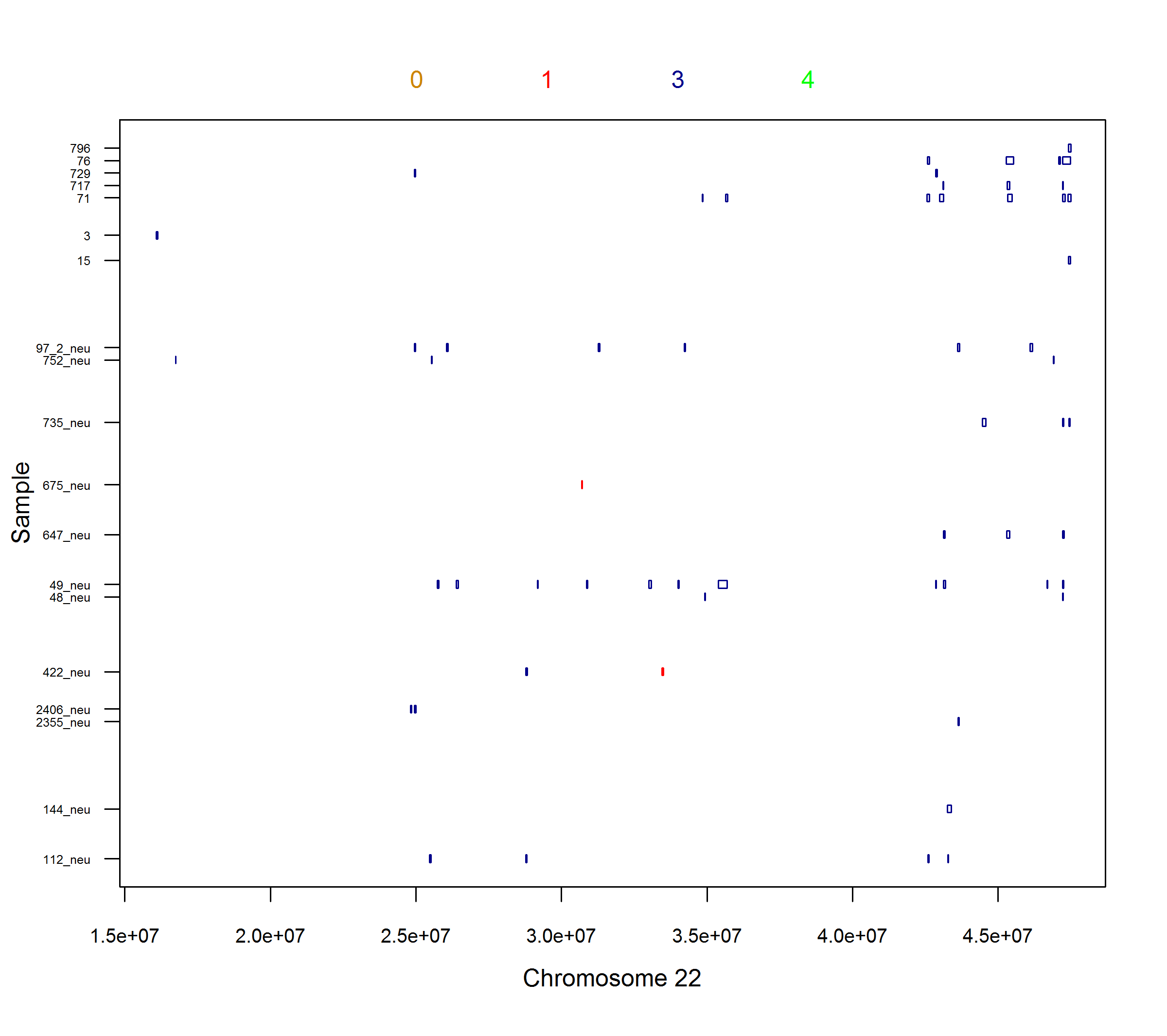
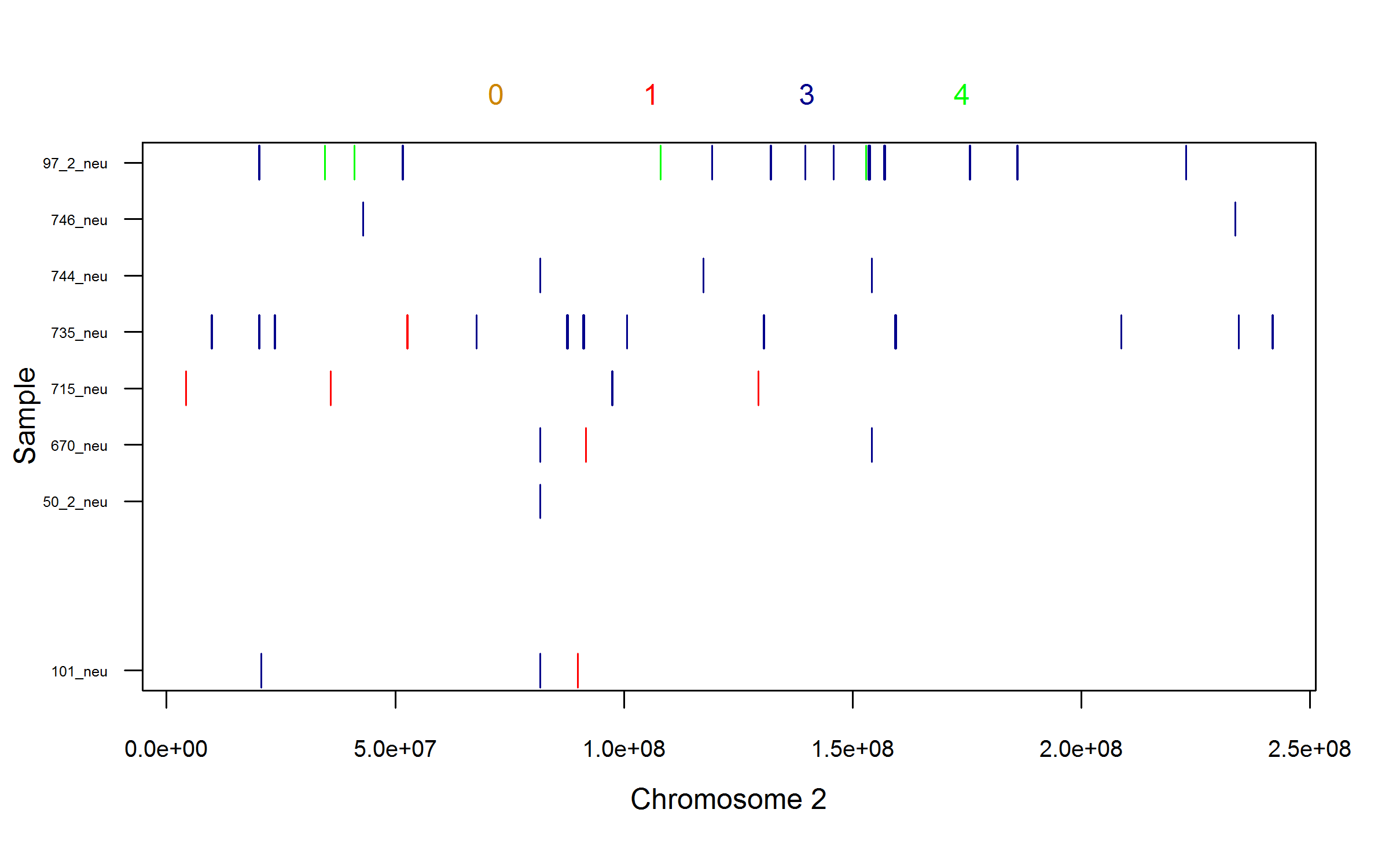
User contributed programs (Uploaded 2010Dec01) : The penncnv_to_plink.pl program can be used to convert PennCNV output into PLINK input format. Run it with -h argument to read the documentation. The program is written and provided by Matthew Gillman at the Wellcome Trust Sanger Institute. User contributed programs (Uploaded 2011Feb27): The plot_raw_PennCNV.R program can plot from PennCNV rawcnv file on screen or to a high solution png file. Example screen shot 1, 2, 3 and 4. This program is written band provided by Dr. Bowang Chen. See updated script below. User contributed programs (Uploaded 2012Jul16): The plot_raw_PennCNV2PDF.R program can plot from PennCNV rawcnv file to a high solution PDF file. This new script exports all plots to a pdf file, by default 70 samples/page (can be changed by users). It is much fast now, it plots a 50000+ line raw file to a 400+ page pdf in ~2 minutes. Example output is here. Example command line is "R CMD BATCH --no-save --no-restore "--args filename=\"$filename\" PDFname=\"$PDFname\"" $path_R/plot_raw_PennCNV2PDF.R ". This program is written band provided by Dr. Bowang Chen@German Cancer Research Center.
This example data set contains genotyping data for a father-mother-offspring trio, genotyped on the Illumina HumanHap550 array. The file is in BeadStudio project format, and can be opened by the Illumina BeadStudio software. The file is used in the tutorial in the web site. This file is an exported text file from the Illumina BeadStudio software using the above project file. It is useful for users without access to BeadStudio to test PennCNV. This “serial dilution” data set contains genotyping data on a sample genotyped five times, each time with ~2-fold dilutions. For more details please see the Diskin et al paper. The file is in BeadStudio project format, and can be opened by the Illumina BeadStudio software.
This package contains PennCNV-Affy protocols and helper scripts for handling Affymetrix Mapping 500K, genome-wide 5.0 and genome-wide 6.0 data as raw CEL files. For instructions on how to use the PennCNV-Affy package, please refer to the PennCNV-Affy link in the menu bar to the left of the page. The package below is updated on 2009Aug27, with very minor bug fixes only. It should produce identical results as previous version.
Genome Browser tracks for commonly used SNP arrays Click any of the link below will load the corresponding track in the UCSC Genome Browser on hg18 coordinate, or 2006 human genome assembly. It may take several minutes to load each of the track. The user can visualize the location of the marker coverage in each specific arrays and compare them with each other. If the user does not want to see the marker names in the browser, the “dense” drop-down menu option can be used in the browser page to display red vertical bars for each marker. All the genome coordinates are also annotated in the PFB file supplied with the PennCNV package. The Illumina data were based on supplied annotation from Illumina's sample files. The Affymetrix data were based on na26 (July 2008) annotation from Affymetrix website.
Please report annotation mistakes/bugs or request for additional arrays.
Archives of older versions of PennCNV The older versions of PennCNV are given below together with one-sentence description of changes. It is highly recommended to use only the latest version. More detailed change log is recorded in the program code per se.
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}